


Liquid AI 是麻省理工学院的衍生公司,是一家总部位于马萨诸塞州波士顿的基础模型公司。
Liquid AI发布了其首个Liquid Foundation Models (LFMs)系列,这是新一代生成式AI模型,非Transformer架构, 能够在不同规模下实现行业领先的性能,同时保持更小的内存占用和更高效的推理能力。
- 包括1B、3B和40B三个语言模型。
- LFM-1B 在1B模型基准测试中表现出色,超越了基于Transformer的模型。
- LFM-3B 在多个基准测试中表现优异,不仅在3B参数中领先,还优于较大的7B和13B模型,且更适合移动和边缘设备。
- LFM-40B 一个 40.3B 专家混合模型 (MoE),专为处理更复杂的任务设计。
模型架构创新
Liquid AI 团队发明了一种叫做“液态神经网络”的架构,这种系统受到大脑的启发。与传统神经网络不同,它的特别之处在于,液态神经网络即使在训练完成后,仍然能够适应新的数据和环境变化,不需要重新调整。这意味着它在处理复杂任务时能够更加灵活和高效,比如分析连续时间内的数据(例如天气预测或股票走势)。
研究不仅证明了液态神经网络能够应对不同类型的数据(可以很好地处理像视频、音频等连续的时间数据(比如时间顺序上的信息),还具备解释性和因果性,**即它不仅能做出决策,还可以解释为什么做出这个决策。**同时在学习新任务时,它能够用更少的资源达到更高的效率。
此外,他们扩展了这种网络,使其能够用于图形数据、控制系统、生成模型等场景,这些技术在诸如自动驾驶、机器人控制等任务中发挥重要作用。
最令人兴奋的部分是,团队还开发了可以处理非常长时间上下文数据的模型,并将其应用于DNA、RNA等生物领域,甚至能帮助设计新的CRISPR基因编辑系统。
LFMs 设计灵感
LFMs 设计灵感来自于几十年来的数学和信号处理技术积累,通过结合动态系统、信号处理和数值线性代数的理论基础,构建了一种通用的 AI 模型,可以高效处理多种类型的顺序数据。
- 动态系统理论:动态系统关注系统随时间的变化,通常用于研究复杂的时序行为。这种理论为 LFMs 提供了一种方式去处理变化的序列数据,比如视频、音频等。
- 信号处理:信号处理是分析、修改和合成信号的科学(如声音、图像、电信号等)。LFMs 通过信号处理技术来处理连续数据,如音频和时间序列数据,使模型能够更好地理解和处理这些类型的数据。
- 数值线性代数:数值线性代数为处理和计算大规模数据提供了数学基础,特别是在优化计算和存储效率方面。例如,如何更快地处理大规模矩阵运算,正是 LFMs 能够实现高效推理和记忆优化的关键。
LFMs 通过这种方法,能够处理各种连续的数据,比如视频、音频、文字和时间序列(像股票数据那样)。
举例来解释
假设你有以下几个任务:
- 任务一:分析视频中的动作
你希望人工智能识别一段视频里的人在做什么,比如是跑步、跳跃还是打篮球。这个视频是连续的图像帧,包含时间信息(动作在不同时间发生的变化)。 - 任务二:识别语音中的指令
你想让AI听到某个指令,比如“打开灯”,并且理解这个指令。语音是连续的音频数据,AI 需要分析声音的波形、频率等来理解说话的内容。 - 任务三:理解一段文字的意思
你有一篇文章,需要AI总结主要观点或者回答文章中的问题。文字是一种顺序数据,AI 需要理解每个词的顺序和它们之间的关系。 - 任务四:预测未来的股票价格
你有历史的股票价格数据,需要AI根据这些时间序列来预测未来的价格走势。股票价格随着时间变化,所以需要AI理解这些数据中的时间模式。
LFMs 的设计就是为了应对这些不同类型的数据任务。不管是视频、语音、文本,还是时间序列,LFMs 都能够处理,因为它的计算核心是基于动态系统理论、信号处理和线性代数的。这些复杂的理论提供了一种方法,让 LFMs 能够更聪明地识别时间或顺序信息,从而做出更准确的判断。
举个具体例子:
假设你正在用 LFMs 开发一个智能家居助手,它需要:
- 通过摄像头识别家里是否有人在运动(视频数据),
- 通过语音助手接收指令(音频数据),
- 根据用户的聊天记录生成回复(文本数据),
- 并且还能根据用户过去的开关灯习惯预测什么时候应该自动开灯(时间序列数据)。
LFMs 就是这种通用的AI模型,它可以通过一个模型,处理所有这些不同的数据类型,而不需要单独为每个任务设计一个专门的AI。
性能表现
不同规模模型的性能表现:
LFMs 分为三个主要规模的模型:1B、3B 和 40B 参数模型,它们在各自类别中均展现了顶尖的性能。
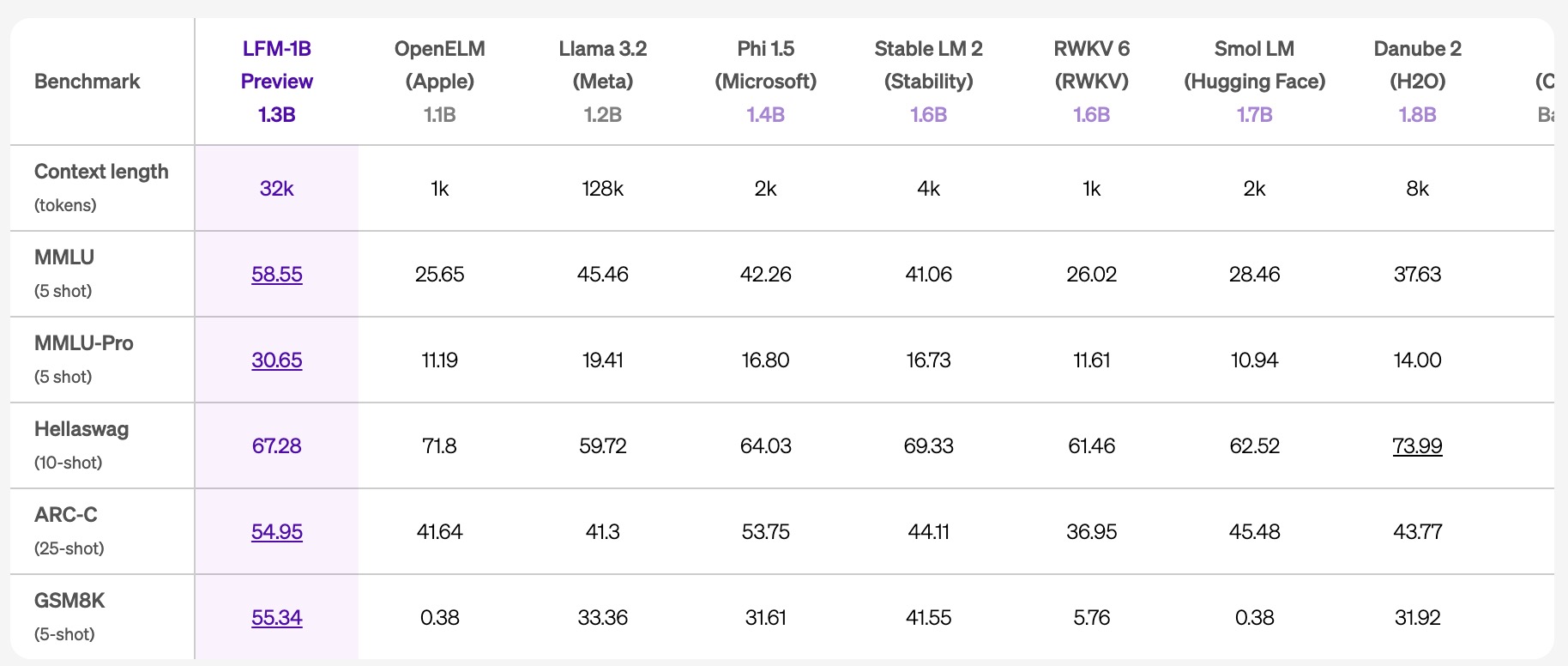
- LFM-1B:在各种基准测试中获得了 1B 类别中的最高分,成为该规模的新最先进模型。这是非 GPT 架构首次显著超越基于 Transformer 的模型。
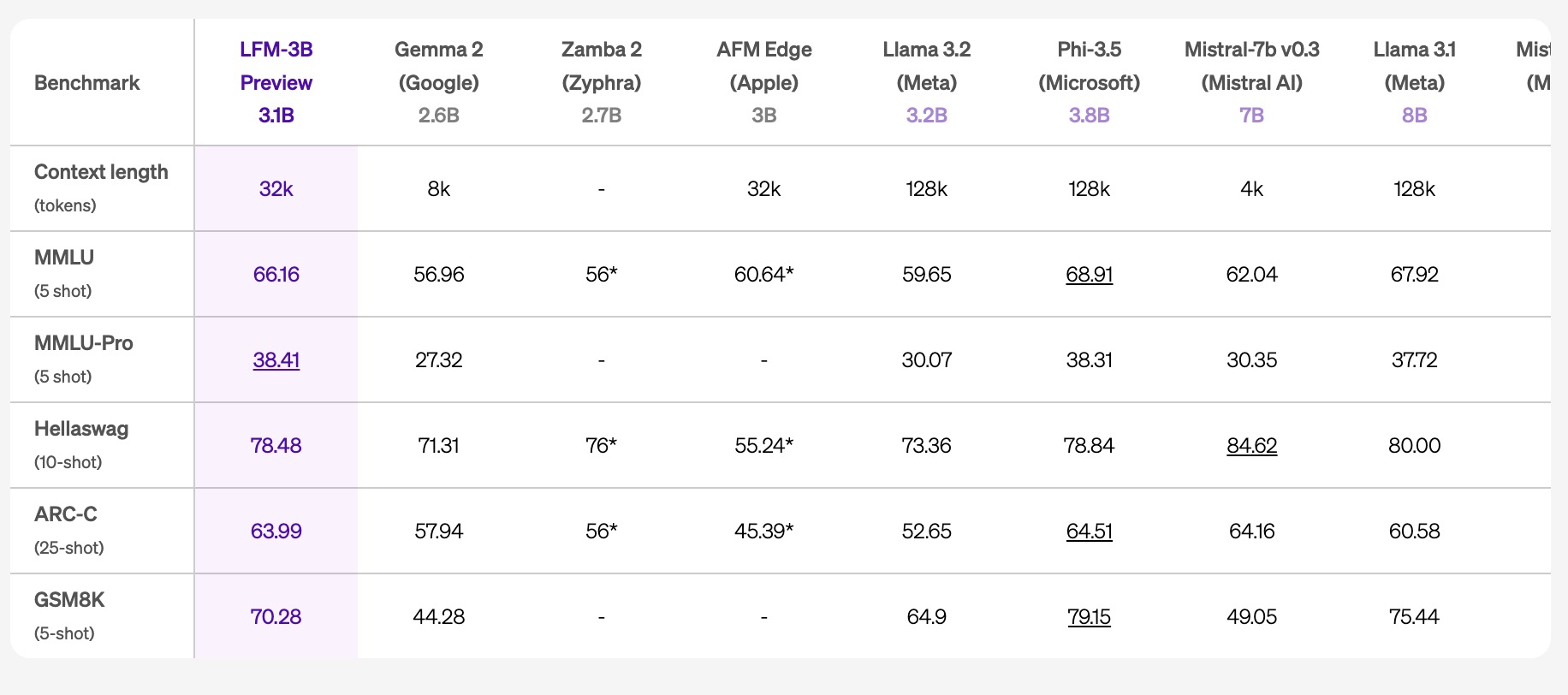
- LFM-3B:提供了其规模下令人难以置信的性能。它在 3B 参数 Transformer、混合模型和 RNN 模型中排名第一,并超越了上一代的 7B 和 13B 模型。它还在多个基准测试中与 Phi-3.5-mini 平分秋色,且比该模型小了18.4%。LFM-3B 是移动和其他边缘文本应用的理想选择。
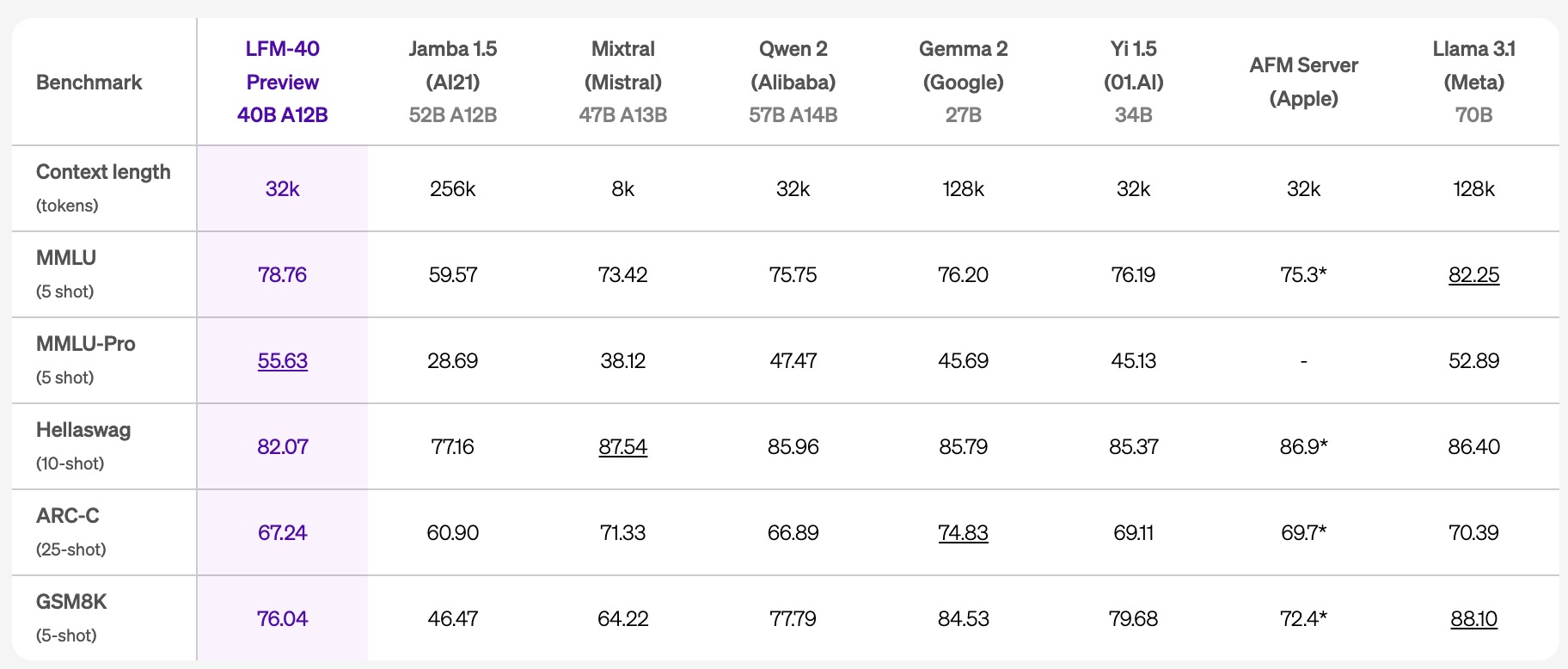
- LFM-40B:该模型使用了12B个激活参数,在性能上能够媲美体积更大的模型,并且其“专家混合”(MoE)架构使其在推理效率上具有显著优势。能够部署在更具成本效益的硬件上。
基准测试表现:
Liquid AI 对 LFMs 进行了广泛的基准测试,以下是一些关键的基准测试结果:
- MMLU (5-shot):LFM-1B 在 MMLU 测试中取得了 58.55 分,超越了同类模型,包括 OpenELM、Llama 3.2 和 Microsoft 的 Phi 1.5。
- Hellaswag (10-shot):LFM-3B 取得了 78.48 分,远超同类 3B 参数模型,并且接近更大规模的 7B 和 8B 模型的得分。
- GSM8K (5-shot):LFM-3B 的得分为 70.28 分,在此类推理任务中表现出色。
- ARC-C (25-shot):LFM-40B 取得了 67.24 分,表现优于多个更大参数的模型,如 AI21 的 Jamba 和 Meta 的 Llama 3.1。
内存效率:
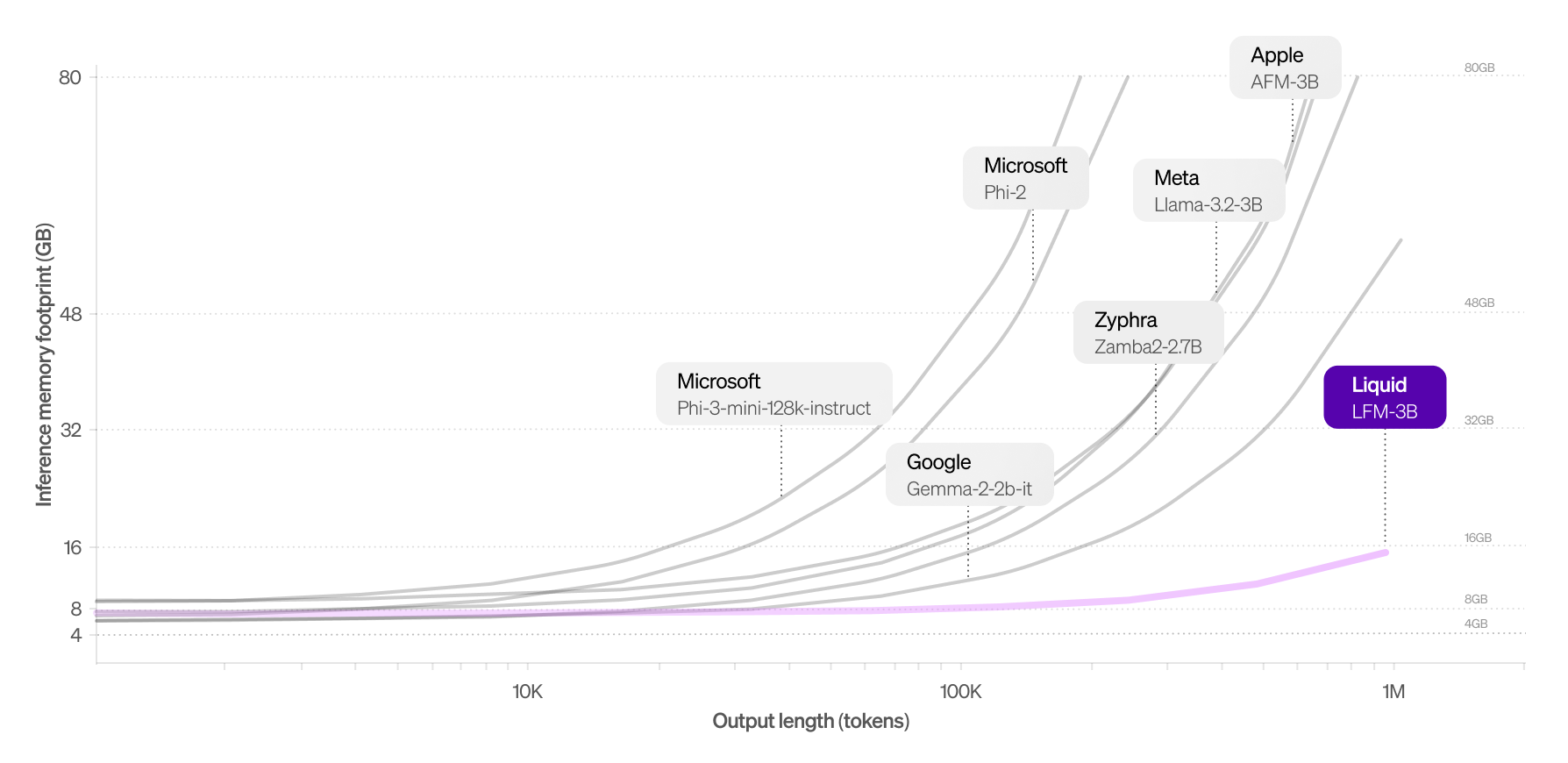
LFMs 在处理长序列输入时表现尤为出色。相比 Transformer 架构,LFMs 的内存占用显著减少,特别是在处理长输入序列时,LFMs 能够在同等硬件条件下处理更长的上下文。例如:
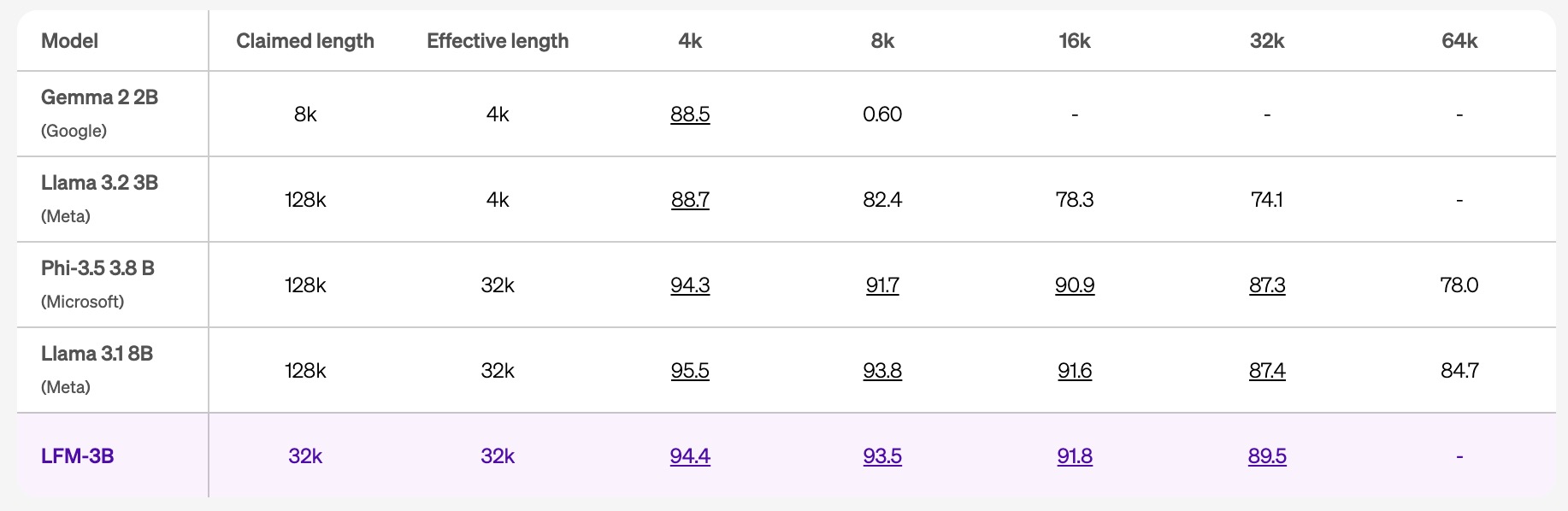
- 在同类 3B 参数模型中,LFM-3B 保持了最小的内存占用,并且在推理过程中大幅降低了KV缓存的增长速度,使其能够处理长达32k tokens的上下文输入。
上下文长度优化:
LFMs 的上下文窗口达到了32k tokens,比许多同类模型的上下文长度更长。根据 RULER 基准测试,LFMs 在不同上下文长度下均表现优异,能够更有效地利用上下文信息,特别是在长上下文任务中具备优势。
推理效率与可扩展性:
- 推理效率:LFMs 的推理效率非常高,能够在较低的计算资源下实现高性能输出。其“专家混合”(MoE)架构在处理复杂任务时展现了优异的性能,并且能够在成本效益和吞吐量上达到平衡。
- 可扩展性:Liquid AI 对 LFMs 的训练和推理管道进行了优化,使得 LFMs 在模型规模、训练时间、推理时间和上下文长度上都具备高度的可扩展性,能够适应不同的硬件平台(如 NVIDIA、AMD、Qualcomm、Cerebras 和 Apple 等)。
评论区